
SDXL 1.0でControlNetのcanny / openpose / Depthを使ってポーズを指定しよう

こんにちは。SDXL 1.0 を利用している中で、ControlNetを利用すると Error となって、使えませんでした。
何で ControlNetを使いたいのかというと、画像の生成サイズが1対1(1024× 1024)の場合、プロンプトに full body や full shot を記載しても、なかなか全身ショットにならず、どうしても上半身の画像が多くなっていました。
そんな中で、
[Major Update] sd-webui-controlnet 1.1.400
を見つけたので、早速試してみました。
はじめに
SDXL 1.0用 ControlNet
画像生成AI「Stable Diffusion」向けの拡張機能で、画像生成AIに対して画面上の棒人間を使ってポーズを指示できる「ControlNet」を作成している米スタンフォード大学のLvmin Zhang氏のGithub(https://github.com/Mikubill/sd-webui-controlnet/discussions/2039)のDiscussionsに
「[Major Update] sd-webui-controlnet 1.1.400 #2039
が投稿されました。(公式サイトの日本語訳(google翻訳)です)
拡張機能 sd-webui-controlnet により、コミュニティからのいくつかの制御モデルのサポートが追加されました。新しいモデルの多くは SDXL に関連しており、Stable Diffusion 1.5 用のモデルもいくつかあります。
sd-webui-controlnet 1.1.400 は、1.6.0 以降の webui 用に開発されました。
新しくサポートされたモデルのリスト:
diffusers_xl_canny_full.safetensors
diffusers_xl_canny_mid.safetensors
diffusers_xl_canny_small.safetensors
diffusers_xl_depth_full.safetensors
diffusers_xl_depth_mid.safetensors
diffusers_xl_depth_small.safetensors
ioclab_sd15_recolor.safetensors
ip-adapter_sd15.pth
ip-adapter_sd15_plus.pth
ip-adapter_xl.pth
kohya_controllllite_xl_depth_anime.safetensors
kohya_controllllite_xl_canny_anime.safetensors
kohya_controllllite_xl_scribble_anime.safetensors
kohya_controllllite_xl_openpose_anime.safetensors
kohya_controllllite_xl_openpose_anime_v2.safetensors
kohya_controllllite_xl_blur_anime_beta.safetensors
kohya_controllllite_xl_blur_anime.safetensors
kohya_controllllite_xl_blur.safetensors
kohya_controllllite_xl_canny.safetensors
kohya_controllllite_xl_depth.safetensors
sai_xl_canny_128lora.safetensors
sai_xl_canny_256lora.safetensors
sai_xl_depth_128lora.safetensors
sai_xl_depth_256lora.safetensors
sai_xl_recolor_128lora.safetensors
sai_xl_recolor_256lora.safetensors
sai_xl_sketch_128lora.safetensors
sai_xl_sketch_256lora.safetensors
sargezt_xl_depth.safetensors
sargezt_xl_depth_faid_vidit.safetensors
sargezt_xl_depth_zeed.safetensors
sargezt_xl_softedge.safetensors
t2i-adapter_xl_canny.safetensors
t2i-adapter_xl_openpose.safetensors
t2i-adapter_xl_sketch.safetensors
t2i-adapter_diffusers_xl_canny.safetensors
t2i-adapter_diffusers_xl_depth_midas.safetensors
t2i-adapter_diffusers_xl_depth_zoe.safetensors
t2i-adapter_diffusers_xl_lineart.safetensors
t2i-adapter_diffusers_xl_openpose.safetensors
t2i-adapter_diffusers_xl_sketch.safetensors
thibaud_xl_openpose.safetensors
thibaud_xl_openpose_256lora.safetensors
以下のメソッドがサポートされていますが、制御モデルは必要ありません
revision (SDXL)
reference (SDXL)
すべてのファイルはhttps://huggingface.co/lllyasviel/sd_control_collection/tree/mainにミラーリングされています(モデルをダウンロードするにはこのリンクを使用してください)
ここに来て、一気にSDXL 1.0用のControlNetの各モデルが、出揃ってきた感じですね。
時間と回線とディスクに余裕がある場合は、全部ダウンロードしてしまいましょう。
SDXL 1.0用 ControlNetのインストール
利用するのはいつも通り、AUTOMATIC1111版web UIでの利用を前提とします。
sd-webui-controlnet 1.1.400はDiscussionsに書かれていたとおり、v.1.6.0以降である必要があります。
![]()
web-ui を起動したら、Extensions タブを押下し、拡張機能管理画面を開きます。
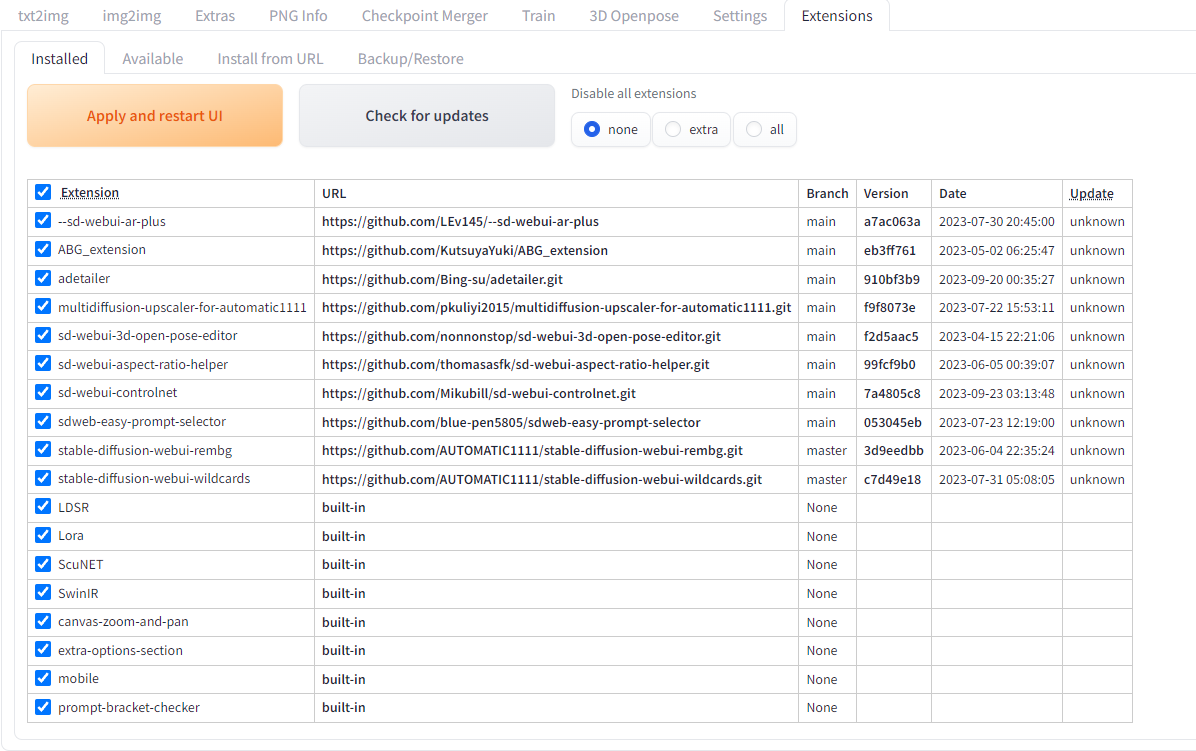
こちらの例ではすでに ControlNetをインストール済みですが、まだ、ControlNetをインストールしていない方は、Install from URL に以下のURLを記載して、Installボタンを押してインストールしてください。
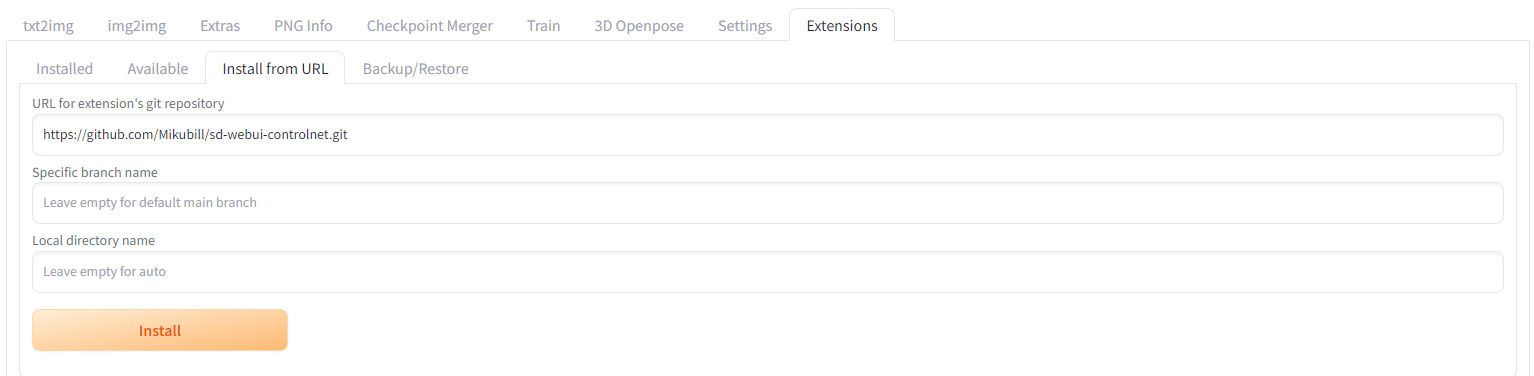
最新のControlNetがインストールできたら、Apply and restart UIボタンを押して、web uiを再起動して最新のControlNetを有効にしてください。
現時点(2023年9月30日)であれば、以下がsd-webui-controlnetの最新バージョンとなります。

あとは、モデルをダウンロードして、以下のディレクトリに配置します。
stable-diffusion-webui\models\ControlNet
ControlNetを使う
ControlNet v1.1.410 の右にある◀をクリックして、ControlNetの画面を開きます。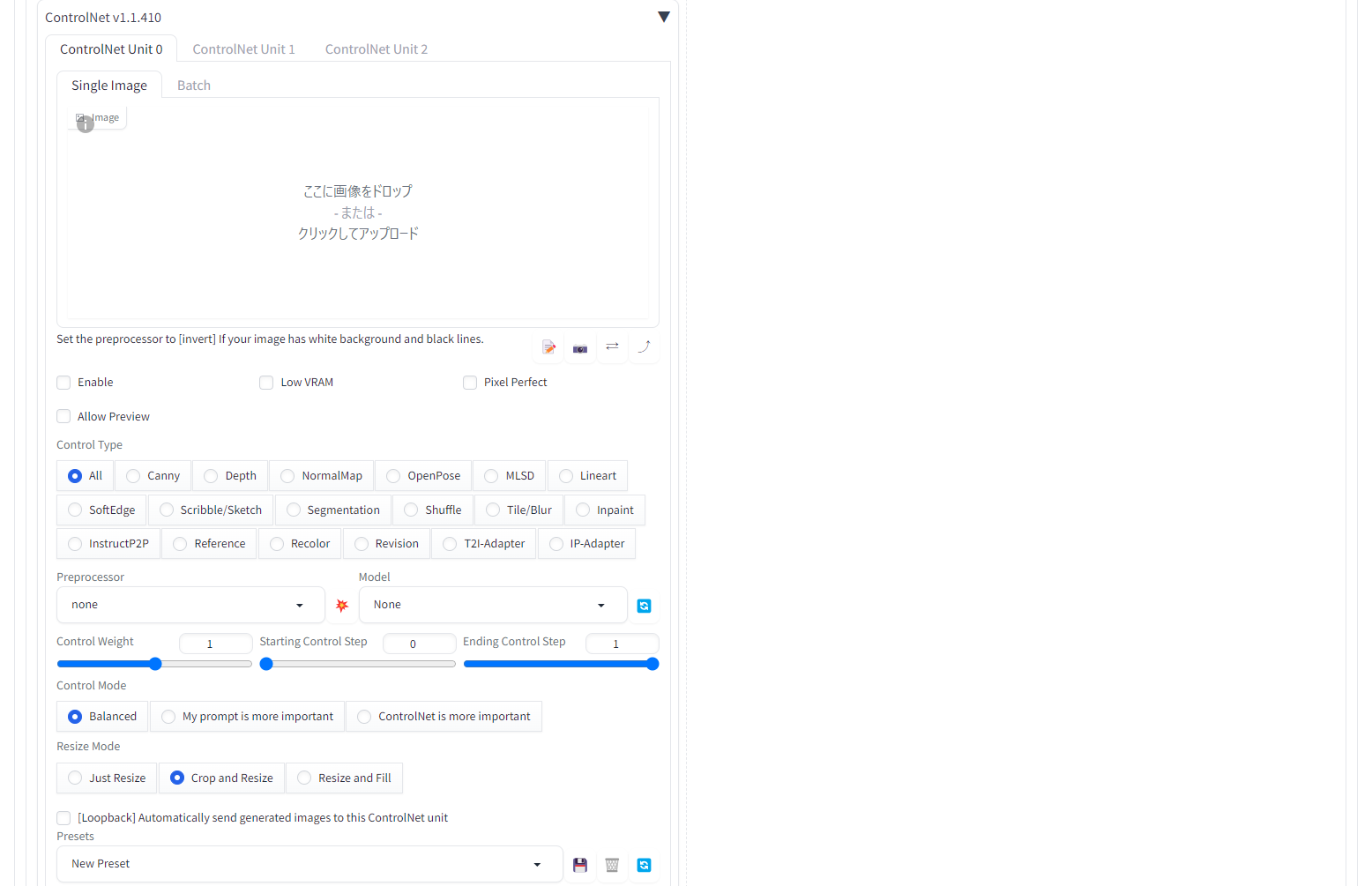
ControlNetを利用する場合は、元になる画像を「ここに画像をドロップまたはクリックしてアップロード」にアップロードし、Enable を☑し、利用するControl Type を選択、さらに、Control Type にあった、Preprocessor と Model を選んだら、後はいつもの画像生成と同様にプロンプトを入力して、Generate ボタンを押すだけです。
また、たくさんのモデルが利用できるようになっていますが、今回は、Discussionsの後半に記載されているkohyaさん作成のControl-LLLiteを利用します。理由は、このモデルは処理も軽く使いやすいからです。
実際に利用する場合には、それぞれ特徴があると思いますので、自分に合ったモデルを探してみてください。
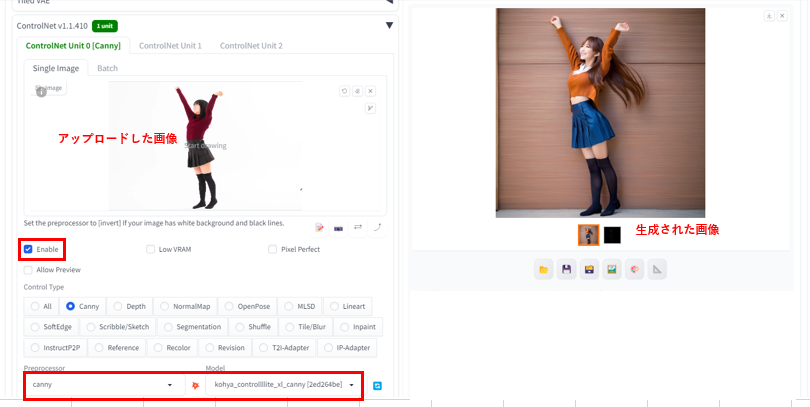
canny 線画でポーズ指定
ここまで忠実にポーズが指定できるのかと驚かされます。
また、ポーズだけではなく、服装も類似して生成されるようですね。
輪郭画像も同時にに出力されるので、保存しておくと、プリプロセッサを指定せずにに、線画からポーズを指定した画像を生成することができます。
利用したモデル:kohya_controllllite_xl_canny
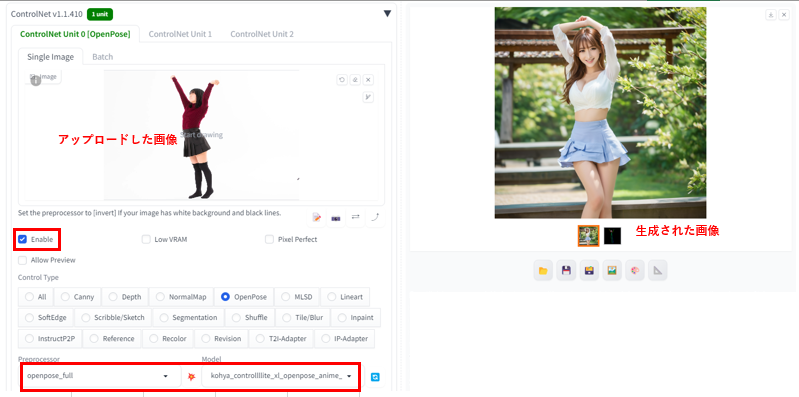
openpose 骨格検出でポーズ指定
元画像から棒人間を抽出してポーズを指定できます。
cannyとは異なり、服装などは類似しないため、ポーズだけを反映したい場合に効果的ですが、棒人間への抽出レベルが悪いのか、ポーズの忠実度があまりよくないです。
骨格の抽出画像(棒人間)も生成されるため、保存しておくと、プリプロセッサを指定せずにに、棒人間からポーズを指定した画像を生成することができます。
利用したモデル:kohya_controllllite_xl_openpose_anime_v2
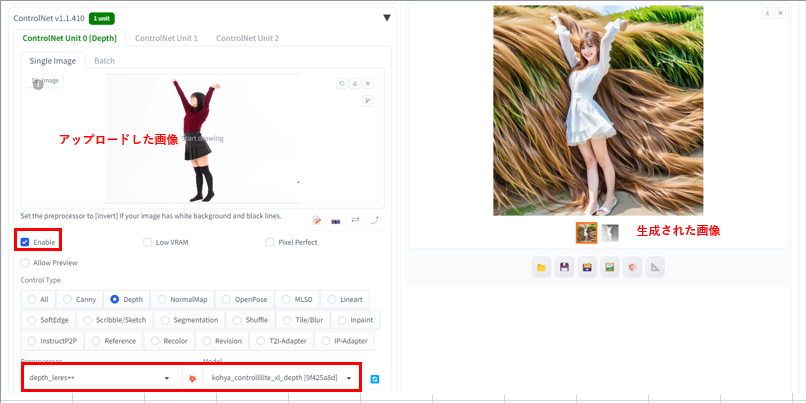
Depth 深度情報からポーズ指定
Depth は奥行きを正確に抽出できるようです。
手前が白色・奥に行くほど黒色で表現されるのが深度マップで、同時に深度マップが作成されるので、保存しておくと、プリプロセッサを指定せずにに、深度マップからポーズを指定した画像を生成することができます。
Depthには以下の4種類があります。
・depth_leres
・depth_leres++
・depth_midas
・depth_zoe
こちらも画像に合わせて使い分けるとよいと思います。
利用したプリプロセッサ:depth_leres++
利用したモデル:kohya_controllllite_xl_depth
まとめ
SDXL 1.0用のControlNetがリリースされたことによって、画像のポーズ指定が簡単になり、SDXL 1.0で生成した作品のクオリティを上げることができるようになりました。また、今回利用したポーズ指定の機能以外にも、SDXL 1.0で利用できるものがありますので、次回またご報告させていただきます。
Stable Diffusionをはじめ、様々なAIが常に進化していますので、チェックしながら最新にトライしてみてください。
きっとあなたにぴったりのAIが見つかると思います。
